RocksDB-源码分析(1)BlockTable 读源码分析
本文讨论了RocksDB的Prefetch和Async机制,在回顾LevelDB的SSTable读流程基础上,深入分析RocksDB的BlockBasedTableReader读流程、Prefetch相关函数及异步读取机制,还介绍了相关类设计和简单测试结果。包括:
- LevelDB的SSTable读流程:分为Open和Get两个步骤,Open包括文件句柄管理、Footer读取等;Get使用二分查找索引定位数据块,缓存优先读取,启用布隆过滤器且所有块未缓存读取时,与文件系统交互6次。
- RocksDB的Open流程:调用FilePrefetchBuffer预取文件尾部获取Footer,加载元索引块等,缓存关键元数据,减少磁盘I/O操作。
- PrefetchTail函数:确定预读取大小和范围,尝试文件系统预取,通过限制浪费比例确保I/O效率提升。
- Get流程:用户发起请求,经过时间戳和过滤块匹配检查,创建索引迭代器遍历索引块和数据块,最终返回结果。
- 异步读取:非阻塞操作,提高并发性,与预取结合进一步提高系统并发处理能力。
- 相关类设计:FilePrefetchBuffer负责预取缓冲区管理;BlockFetcher独立Block的异步化读取操作,结合多种缓存和Prefetch机制。
- 简单测试:生成测试命令,对比启用和禁用异步扫描的测试结果,RocksDB的Prefetch和Async机制优化了读取性能。
LevelDB SSTable读回顾
先简单来回顾一下LevelDB中的SSTable读流程,其时序逻辑如下图所示:
sequenceDiagram
participant Client
participant DBImpl
participant Version
participant TableCache
participant Table
participant Block
participant BlockIter
participant FileSystem
Client->>DBImpl: Get(key)
DBImpl->>Version: Get()
activate Version
Version->>MemTable: Get()
activate MemTable
MemTable-->>Version: Not Found
deactivate MemTable
Version->>ImmutableMemTable: Get()
activate ImmutableMemTable
ImmutableMemTable-->>Version: Not Found
deactivate ImmutableMemTable
Note right of Version: SSTable Lookup
Version->>TableCache: Get(file_number)
activate TableCache
TableCache->>TableCache: FindTable
alt Table Not Cached
TableCache->>FileSystem: NewRandomAccessFile
activate FileSystem
FileSystem-->>TableCache: file_handle
deactivate FileSystem
TableCache->>Table: Open
activate Table
Table->>FileSystem: ReadFooter
activate FileSystem
FileSystem-->>Table: footer_data
deactivate FileSystem
Table->>FileSystem: ReadIndexBlock
activate FileSystem
FileSystem-->>Table: index_block
deactivate FileSystem
Table->>Block: new IndexBlock
end
Table->>Block: NewIterator
Block-->>Table: index_iter
Table->>index_iter: Seek(key)
activate index_iter
loop Binary Search
index_iter->>BlockIter: FindMidPoint
BlockIter->>BlockIter: CompareKeys
alt Key < Mid
BlockIter->>BlockIter: AdjustLeft
else
BlockIter->>BlockIter: AdjustRight
end
end
index_iter->>BlockIter: LinearScan
BlockIter-->>index_iter: FoundHandle
deactivate index_iter
Table->>Table: BlockReader
alt CacheHit
Table->>BlockCache: Lookup
BlockCache-->>Table: cached_block
else
Table->>FileSystem: ReadDataBlock
activate FileSystem
FileSystem-->>Table: raw_block
deactivate FileSystem
Table->>Block: new DataBlock
Table->>BlockCache: Insert
end
Table->>Block: NewIterator
Block-->>Table: data_iter
Table->>data_iter: Seek(key)
activate data_iter
loop Binary Search
data_iter->>BlockIter: FindRestartPoint
BlockIter->>BlockIter: CompareEntries
end
loop LinearScan
BlockIter->>BlockIter: ParseNextKey
alt KeyMatch
BlockIter->>BlockIter: ReturnValue
end
end
data_iter-->>Table: value
deactivate data_iter
Table-->>TableCache: value
deactivate Table
TableCache-->>Version: value
deactivate TableCache
Version-->>DBImpl: value
deactivate Version
DBImpl-->>Client: value
简单来说,上述的流程主要分为Open和Get两个步骤,其中,Get触发TableFind后,会调用Open并向缓存中写入对该Table的句柄:
SSTable 查找入口
通过 Version 对象获取 SSTable 元数据;
调用 TableCache 获取对应的 SSTable 实例(使用 LRU 缓存);
Open 流程:
文件句柄管理:通过 FileSystem 打开文件;
Footer 读取:获取索引块和元数据块的位置;
Index Block 读取:建立 key 到数据块的映射关系
Get流程:
使用二分查找索引快速定位 key 所在的数据块
内部通过 BlockIter 实现:
先通过 FindMidPoint 进行二分比较
再通过 LinearScan 进行精确匹配
数据块读取
缓存优先策略:
先检查 BlockCache(默认大小 8MB)
未命中时从文件读取并更新缓存
数据块查找过程
再次使用二分查找定位重启点
线性扫描块内条目进行精确匹配
解析出 key-value 对并返回结果
在经典LevelDB结构中,在启用布隆过滤器且所有块未缓存读取的情况下,SSTable时与文件系统的交互次数如下所示:
打开SSTable文件,
NewRandomAccessFile:首次访问时创建文件句柄;读取Footer元数据,从文件末尾读取48字节校验元数据
读取索引块(Index Block),根据Footer定位并读取索引块
读取元数据块(Metaindex Block),解析Footer获取元数据块位置并读取,用于定位过滤器
读取过滤块(Filter Block),从元数据块解析过滤块位置并读取
读取数据块(Data Block),通过索引块找到目标数据块的位置并读取
总计:6次文件交互
BlockBasedTable Format
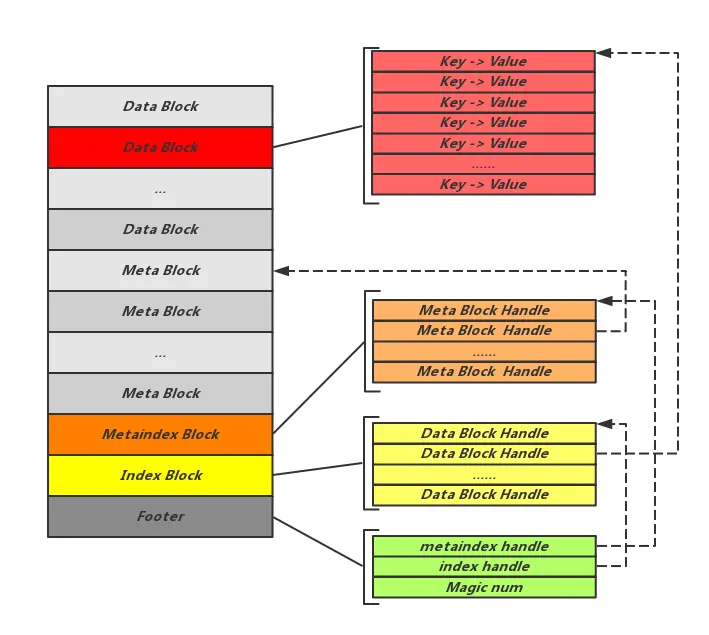
如图所示,SST 文件从头到尾分成5个部分:
一个 block默认的block大小为4k,通常设置为64k(对应配置项:table_options.block_size)。
rocksdb的 sst 文件源于leveldb,主要的区别就是在于 MetaBlock 部分,rocksdb 的内容更多,leveldb 的 MetaBlock 当前只有 Filter 的内容。
- Footer 固定48字节 指出 IndexBlock 和 MetaIndexBlock 在文件中的偏移量信息,它是元信息的元信息,它位于 sstable 文件的尾部;
- IndexBlock 占用一个 block 空间 记录了 DataBlock 相关的元信息;
- MetaIndexBlock 占用一个 block 空间 各个元信息的Block,包括Filter、Properties(整个table的属性信息)、Compression dictionary、Range deletion tombstone;
- MetaBlock 可能占用多个 block空间 存储布隆过滤器的二进制数据 及其他元信息数据;
- DataBlock 可能占用多个 block空间 存储实际的数据即键值对内容
BlockBasedTableReader 读流程
RocksDB截止到编写该文档之前拥有多种文件结构,而BlockBasedTableFormat就是最常见的SST结构,在开始下面的章节之前,希望能够带着一些问题看具体的设计:
当我们在谈论Prefetch时,我们到底在谈论什么?
Prefetch和Cache的区别在什么地方?
异步IO和Prefetch和缓存结构在LSM结构下如何协同工作?
Open 流程
sequenceDiagram
participant User
participant BlockBasedTable
participant FilePrefetchBuffer
participant BlockFetcher
participant Cache
participant Filter
participant IndexReader
User->>BlockBasedTable: Open(file, options)
BlockBasedTable->>FilePrefetchBuffer: PrefetchTail
FilePrefetchBuffer-->>BlockBasedTable: PrefetchBuffer initialized
BlockBasedTable->>BlockFetcher: ReadFooterFromFile
BlockFetcher-->>BlockBasedTable: Footer read
BlockBasedTable->>BlockFetcher: ReadMetaIndexBlock
BlockFetcher-->>BlockBasedTable: Metaindex block read
BlockBasedTable->>BlockFetcher: ReadPropertiesBlock
BlockFetcher-->>BlockBasedTable: Properties block read
BlockBasedTable->>BlockFetcher: ReadRangeDelBlock
BlockFetcher-->>BlockBasedTable: Range deletion block read
BlockBasedTable->>IndexReader: CreateIndexReader
IndexReader-->>BlockBasedTable: Index reader created
BlockBasedTable->>Filter: CreateFilterBlockReader
Filter-->>BlockBasedTable: Filter reader created
BlockBasedTable->>Cache: Insert index and filter blocks
Cache-->>BlockBasedTable: Blocks cached
BlockBasedTable-->>User: Table reader returned
简单来说,RocksDB的Open函数也是在同样的流程逻辑中被调用,当memtable查询实效后,转而在version列表中查找,如果TableCache不命中已经hold在内存中的Table,那么就需要调用Open开始新的SSTable读入,同时,具体的:
BlockBasedTable 调用 FilePrefetchBuffer 预取文件尾部,获取Footer;
读取文件 Footer,通过 BlockFetcher 读取文件末尾的 48 字节 Footer,包含元索引块、索引块等关键元数据的位置信息;
加载元索引块,根据 Footer 定位MetaIndex Block,元索引块存储属性块、过滤器块等元数据的位置信息;
读取属性块,解析 SSTable 属性(键数量、压缩类型等),为后续读取提供必要的配置信息;
加载范围删除,读取并解析 Range Deletion Block,记录文件中被删除的键范围信息;
创建索引读取器,基于索引块创建 IndexReader;
初始化过滤器读取器,创建 FilterBlockReader,读取相应的布隆过滤器;
缓存关键元数据,将索引块和过滤器块存入 Cache,减少后续读取时的磁盘 I/O 操作;
返回完成初始化的TableReader。
结合上述LevelDB的Open 流程,实际上这里会发生多次File文件指针的读取,那么RocksDB首先做的就是调用PrefetchTail把相应的Footer都load到内存中来。
PrefetchTail 函数
graph TD
A[开始] --> B[确定预读取大小]
B --> C{tail_size != 0?}
C -->|是| D[使用 tail_size 作为预读取大小]
C -->|否| E[从 tail_prefetch_stats 获取建议大小]
E --> F{获取成功?}
F -->|是| G[使用建议大小]
F -->|否| H[使用默认大小]
H --> J[计算预读取范围]
J --> K{文件大小 < 预读取大小?}
K -->|是| L[从文件开头读取整个文件]
K -->|否| M[从文件尾部向前计算预读取范围]
M --> N[尝试文件系统预取]
N --> O{文件系统支持预取?}
O -->|是| P[使用文件系统预取]
O -->|否| Q[创建 FilePrefetchBuffer]
L --> R[尝试文件系统预取]
R --> S{文件系统支持预取?}
S -->|是| T[使用文件系统预取]
S -->|否| U[创建 FilePrefetchBuffer]
T --> V[返回成功状态]
U --> W[使用 FilePrefetchBuffer 预取]
W --> V
P --> V
Q --> W
V[返回成功状态] --> X[结束]
确定预读取大小:
如果
tail_size不为 0,直接使用该值。否则,尝试从
tail_prefetch_stats获取建议大小。如果获取失败,则根据prefetch_all和preload_all参数使用默认值(512 KB 或 4 KB)。
计算预读取范围:
如果文件大小小于预读取大小,则从文件开头读取整个文件。
否则,从文件尾部向前计算预读取的起始偏移量和长度。
尝试文件系统预取:
如果文件系统支持预取,则直接使用文件系统的预取功能。
如果文件系统不支持预取,则创建一个
FilePrefetchBuffer实例,并使用它来执行预读取操作。
返回成功状态:
- 无论使用哪种预取方式,最终都会返回成功状态。
关于tail_prefetch_stats的设计,一言以蔽之,通过限制浪费比例(≤12.5%),确保预取带来的I/O效率提升不会被过多的空间浪费抵消:
- 数据结构与数据收集
环形缓冲区:使用固定大小的环形缓冲区
records_存储最近的kNumTracked次有效预取长度。当新数据到达时,覆盖旧数据,保持最新的记录。RecordEffectiveSize方法:记录每次预取的有效长度,维护数据的更新。
算法步骤:
a. 数据准备
- 复制并排序历史数据:将缓冲区中的数据复制到
sorted向量中,并按升序排序。排序后便于后续遍历和计算。b. 遍历候选预取大小
初始化参数:
prev_size记录前一个候选大小,max_qualified_size记录当前满足条件的最大候选,wasted累计浪费量。遍历排序后的数据:从第二个元素开始(i=1),逐个计算每个候选的浪费情况。
计算总读取量:
read = sorted[i] * sorted.size(),假设所有历史记录均按当前候选大小预取。更新浪费量:
wasted += (sorted[i] - prev_size) * i。增量浪费为当前候选与前一个候选的差值乘以之前的记录数(i个记录会被填充到当前候选大小)。判断条件:若累计浪费
wasted ≤ read / 8,则当前候选大小合格,更新max_qualified_size。c. 确定最终预取大小
上限限制:设置最大预取大小
kMaxPrefetchSize=512KB,避免过度预取。返回结果:取
max_qualified_size与kMaxPrefetchSize的较小值作为最终建议值。
- 核心逻辑
浪费计算:假设历史记录按升序排列为
[A, B, C, D, E],当候选为C时:
所有记录的预取大小均设为C。
总读取量为
C * 5。浪费量为:
(B - A)*1 + (C - B)*2(前两个记录的浪费)。条件判断:若浪费不超过总读取量的1/8,则认为该候选大小合理。
示例
假设Prefetch历史记录排序后为
[64KB, 128KB, 256KB, 512KB]:
候选256KB时:
总读取量:
256KB * 4 = 1024KB。浪费:
(128-64)*1 + (256-128)*2 = 64 + 256 = 320KB。条件:
320KB ≤ 1024KB/8 = 128KB→ 不满足,故256KB不合格。候选128KB时:
总读取量:
128KB * 4 = 512KB。浪费:
(128-64)*1 = 64KB。条件:
64KB ≤ 512KB/8 = 64KB→ 满足,故128KB合格。最终建议值为128KB(若未超过512KB上限)。
ReadFooterFromFile 函数
graph TD
A[开始] --> B[检查文件大小]
B -->|文件大小小于最小编码长度| C[返回错误]
B -->|文件大小足够| D[准备读取缓冲区]
D --> E[确定读取偏移量]
E --> F[尝试从预取缓冲区读取]
F -->|预取缓冲区中有数据| G[读取数据成功]
F -->|预取缓冲区中无数据| H[从文件读取]
H -->|使用直接 I/O| I[通过 AlignedBuf 读取]
H -->|不使用直接 I/O| J[直接读取到 footer_buf]
I --> K[检查读取结果]
J --> K
K -->|读取失败| L[返回错误]
K -->|读取成功| M[验证读取数据]
M -->|数据不完整| N[获取实际文件大小并返回错误]
M -->|数据完整| O[解析 Footer 数据]
O --> P[验证魔数]
P -->|验证失败| Q[返回错误]
P -->|验证成功| R[返回成功]
G --> M
R[返回成功] --> S[结束]
L --> S
N --> S
Q --> S
ReadFooterFromFile 函数用于从文件中读取 SST 文件的 Footer,并验证其完整性。Footer 包含了文件的魔数(Magic Number)和元数据块的块句柄等重要信息。
prefetch 在这里的作用:
在
ReadFooterFromFile函数中,prefetch的作用是尝试从预取缓冲区中读取 Footer 数据。如果预取缓冲区中已经包含了所需的 Footer 数据,则可以直接使用,避免了从磁盘读取的开销。这在顺序读取或频繁访问相同文件的情况下特别有用,可以显著提高读取性能。具体来说,
prefetch_buffer->TryReadFromCache方法会检查预取缓冲区中是否包含指定偏移量和长度的数据。如果包含,则直接返回数据;如果不包含,则返回 false,表示需要从文件中读取数据。
ReadMetaIndexBlock 函数
graph TD
A[开始] --> B[创建 BlockFetcher 对象]
B --> C{启用异步读取且预取缓冲区存在?}
C -->|是| D[调用 ReadAsyncBlockContents]
C -->|否| E[调用 ReadBlockContents]
D --> F[尝试从持久化缓存获取未压缩块]
F -->|成功| G[设置压缩类型为无压缩并返回成功]
F -->|失败| H[尝试从持久化缓存获取序列化块]
H -->|失败| I[使用预取缓冲区异步预取数据块]
I --> J[处理预取数据]
J --> K[处理数据块的拖尾信息]
K --> L{需要重新读取?}
L -->|是| M[重新读取数据块]
L -->|否| N[解压缩或获取块内容]
N --> O[插入未压缩块到持久化缓存]
O --> P[返回成功]
E --> Q[尝试从持久化缓存获取未压缩块]
Q -->|成功| R[设置压缩类型为无压缩并返回成功]
Q -->|失败| S[尝试从预取缓冲区获取数据]
S -->|成功| T[处理读取错误]
S -->|失败| U[从文件读取数据块]
U --> V[处理读取错误]
V --> W[解压缩或获取块内容]
W --> X[插入未压缩块到持久化缓存]
X --> Y[返回成功]
P --> Z[结束]
Y --> Z
ReadMetaIndexBlock 函数用于从文件中读取并解析 SST 文件的元数据索引块(Meta Index Block)。元数据索引块包含文件中其他元数据块(如属性块、过滤器块等)的块句柄,对于后续访问这些元数据块至关重要。
这里有几个关键的函数:
入口函数 ReadMetaIndexBlock
创建 Meta Index Block 对象:创建一个
Block_kMetaIndex对象,用于存储读取和解析后的元数据索引块。调用辅助函数:调用
ReadAndParseBlockFromFile函数,传入文件、预取缓冲区、页脚、读取选项、块句柄等参数,读取并解析元数据索引块。错误处理:如果读取失败,记录错误日志并返回错误状态。
返回结果:将解析后的元数据索引块和其迭代器返回给调用者。
辅助函数
ReadAndParseBlockFromFile
创建 BlockFetcher 对象:根据传入的参数创建一个
BlockFetcher对象,用于处理块的读取和解析。异步读取或同步读取:根据是否启用异步读取和预取缓冲区的存在,选择调用
ReadAsyncBlockContents或ReadBlockContents。解析块内容:如果读取成功,使用
BlockCreateContext创建并解析块内容。返回状态:返回读取和解析的结果状态。
辅助类
BlockFetcher
ReadAsyncBlockContents
尝试从持久化缓存获取未压缩块:如果成功获取,设置压缩类型为无压缩并返回成功。
尝试从持久化缓存获取序列化块:如果失败,使用预取缓冲区异步预取数据块。
处理预取数据:如果预取成功,处理数据块的拖尾信息;如果需要,重新读取以修复损坏的数据块。
解压缩或获取块内容:根据是否需要解压缩,对数据块进行相应的处理。
插入未压缩块到持久化缓存:如果需要,将未压缩的块插入到持久化缓存中。
辅助类
ReadBlockContents
尝试从持久化缓存获取未压缩块:如果成功获取,设置压缩类型为无压缩并返回成功。
尝试从预取缓冲区获取数据:如果预取缓冲区中有数据,直接使用;否则从文件中读取数据块。
处理读取错误:如果读取失败且支持重新读取,尝试重新读取数据块。
解压缩或获取块内容:根据是否需要解压缩,对数据块进行相应的处理。
插入未压缩块到持久化缓存:如果需要,将未压缩的块插入到持久化缓存中。
prefetch 在这里的作用:
再次减少磁盘 I/O 次数:通过预取机制,在读取当前数据块的同时,预测并提前读取可能需要的后续数据块,减少磁盘 I/O 次数。
提高读取性能:预取的数据块存储在内存缓冲区中,后续读取时可以直接从缓冲区获取,避免了频繁的磁盘读取操作,提高了读取性能。
支持异步读取:与异步读取结合,允许在不阻塞主线程的情况下预取数据,进一步提高系统的并发处理能力。
异步读取:
非阻塞操作:异步读取允许在提交读取请求后立即返回,而不等待数据实际读取完成,避免等待。
提高并发性:在等待异步读取完成的同时,可以提前开始Get。
但是针对BlockFetcher这里并没有进行展开,其中封装了对ReadBlock的诸多处理逻辑,这部分在下文展开。
PrefetchIndexAndFilterBlocks 函数
1 | 函数 PrefetchIndexAndFilterBlocks(ro, prefetch_buffer, meta_iter, new_table, prefetch_all, table_options, level, file_size, max_file_size_for_l0_meta_pin, lookup_context): |
入口函数 PrefetchIndexAndFilterBlocks
查找过滤器块句柄和类型:
根据过滤器策略的兼容名称,尝试查找不同类型的过滤器块(如全量过滤器、分区过滤器等)。
如果找到,设置过滤器类型和块句柄;如果找到的是过时的过滤器类型,记录警告日志。
查找压缩字典块句柄:
- 调用
FindOptionalMetaBlock查找压缩字典块的块句柄。
- 调用
确定缓存和预读取策略:
- 根据配置和文件级别,确定是否缓存和预读取索引块、过滤器块和压缩字典块。
创建索引读取器:
根据索引类型,创建相应的索引读取器(如分区索引读取器、二分查找索引读取器等)。
如果是哈希索引,检查是否缺少前缀提取器,如果是,则回退到二分查找索引。
缓存依赖的索引块分区:
- 如果需要预读取或缓存分区,调用索引读取器的
CacheDependencies方法。
- 如果需要预读取或缓存分区,调用索引读取器的
创建过滤器块读取器:
根据过滤器类型,创建相应的过滤器块读取器(如分区过滤器块读取器、全量过滤器块读取器等)。
如果需要预读取或缓存分区,调用过滤器块读取器的
CacheDependencies方法。
创建压缩字典读取器:
- 如果存在压缩字典块句柄,创建压缩字典读取器。
辅助函数
FindOptionalMetaBlock和FindMetaBlock
查找元数据块:
使用元数据索引迭代器查找指定名称的元数据块。
如果找到,解析块句柄并返回;如果未找到,返回空块句柄和相应状态。
辅助函数
CreateIndexReader
确定索引块句柄:
- 根据文件页脚格式版本,从页脚中获取索引块句柄,或通过元数据索引迭代器查找。
创建索引读取器:
- 根据索引类型,创建相应的索引读取器。
辅助函数
CreateFilterBlockReader
创建过滤器块读取器:
- 根据过滤器类型,创建相应的过滤器块读取器。
辅助函数
UncompressionDictReader::Create和ReadUncompressionDictionary
读取压缩字典:
如果需要预读取或不使用缓存,读取压缩字典块并缓存。
创建压缩字典读取器。
Get 流程
sequenceDiagram
participant User
participant BlockBasedTable
participant FilterBlockReader
participant IndexIterator
participant DataBlockIter
participant BlockCache
participant Prefetcher
User->>BlockBasedTable: Get(key)
BlockBasedTable->>BlockBasedTable: TimestampMayMatch()
alt Timestamp不匹配
BlockBasedTable-->>User: 返回Status::OK()
else
BlockBasedTable->>FilterBlockReader: FullFilterKeyMayMatch()
FilterBlockReader-->>BlockBasedTable: may_match
alt may_match=false
BlockBasedTable-->>User: 返回Status::OK()
else
BlockBasedTable->>IndexIterator: NewIndexIterator()
IndexIterator->>BlockBasedTable: iiter
loop 遍历索引块
BlockBasedTable->>IndexIterator: Seek(key)
IndexIterator->>BlockBasedTable: 返回IndexValue(v)
BlockBasedTable->>BlockBasedTable: NewDataBlockIterator()
BlockBasedTable->>Prefetcher: PrefetchIfNeeded()
Prefetcher->>BlockCache: 检查/预取数据块
BlockCache-->>Prefetcher: 数据块句柄
BlockBasedTable->>DataBlockIter: SeekForGet(key)
DataBlockIter->>BlockBasedTable: may_exist
alt may_exist
loop 遍历数据块条目
DataBlockIter->>GetContext: SaveValue()
GetContext-->>DataBlockIter: 是否继续
end
end
end
end
end
BlockBasedTable-->>User: 返回Status
用户发起请求
- 用户调用
BlockBasedTable的Get(key)方法,传入要查找的键key,启动数据获取流程。
- 用户调用
时间戳匹配检查
BlockBasedTable接收到请求后,首先调用自身的TimestampMayMatch()方法,检查当前时间戳是否匹配。如果时间戳不匹配,
BlockBasedTable直接向用户返回Status::OK(),表示操作完成但未找到匹配数据,流程结束。如果时间戳匹配,流程进入下一步。
过滤块匹配检查
BlockBasedTable调用FilterBlockReader的FullFilterKeyMayMatch()方法,传入完整过滤键,检查该键是否可能在过滤块中匹配。FilterBlockReader执行匹配检查后,将结果may_match返回给BlockBasedTable。如果
may_match为false,说明过滤块中明确不存在该键,BlockBasedTable向用户返回Status::OK(),流程结束。如果
may_match为true,说明过滤块中可能存在该键,流程继续。
创建索引迭代器
BlockBasedTable调用IndexIterator的NewIndexIterator()方法,创建一个新的索引迭代器。IndexIterator返回创建好的索引迭代器iiter给BlockBasedTable。
遍历索引块
进入循环,遍历索引块:
BlockBasedTable调用IndexIterator的Seek(key)方法,在索引块中查找与键key匹配的索引项。IndexIterator返回找到的索引值v给BlockBasedTable。BlockBasedTable根据索引值v,调用自身的NewDataBlockIterator()方法,创建一个新的数据块迭代器。BlockBasedTable调用Prefetcher的PrefetchIfNeeded()方法,检查是否需要进行数据预取。Prefetcher检查或预取数据块,与BlockCache交互,获取数据块句柄,并将句柄返回给Prefetcher。BlockBasedTable调用DataBlockIter的SeekForGet(key)方法,在数据块中查找键key。DataBlockIter返回是否可能存在匹配数据的标志may_exist给BlockBasedTable。如果
may_exist为true,进入一个循环,遍历数据块条目:DataBlockIter调用GetContext的SaveValue()方法,保存找到的值。GetContext返回是否继续遍历的指示给DataBlockIter。
循环结束后,继续遍历索引块,直到所有可能的索引项都被检查完毕。
返回结果给用户
- 完成所有遍历和查找操作后,
BlockBasedTable向用户返回最终的Status,表示数据获取操作的结果。
- 完成所有遍历和查找操作后,
再次重申相关类的职责的划分:
BlockBasedTable:作为核心协调者,负责接收用户请求,进行初步的时间戳和过滤块匹配检查,创建和管理索引迭代器及数据块迭代器,与预取器交互,以及最终将结果返回给用户。
FilterBlockReader:负责执行过滤块的匹配检查,快速筛选出不可能包含目标键的块,提高查找效率。
IndexIterator:用于遍历索引块,查找与目标键匹配的索引项,提供索引值以便进一步定位数据块。
DataBlockIter:在数据块中进行具体的数据查找,根据给定的键定位到对应的条目,并与GetContext协作保存找到的值。
BlockCache:缓存数据块,提高数据访问速度,当需要预取数据块时,提供数据块句柄。
Prefetch:负责根据需要进行数据预取操作,提前将可能需要的数据块加载到缓存中,减少后续访问的延迟。
BlockBasedTableIterator SeekImpl
graph TD
A[开始SeekImpl] --> B{首次调用?}
B -- 是 --> C[设置seek_key_prefix_for_readahead_trimming_]
C --> D[重置缓存查找变量]
D --> E{自动调整readahead_size?}
E -- 是 --> F[设置readahead_cache_lookup_=true]
E -- 否 --> G
F --> G[CheckPrefixMayMatch]
G -- 前缀不匹配 --> H[重置数据迭代器]
G -- 匹配 --> I{需要重新定位索引?}
I -- 是 --> J[IndexIterator.Seektarget]
I -- 否 --> K[检查是否同一数据块]
J --> K
K --> L{同一数据块且有效?}
L -- 是 --> M[直接使用现有数据块迭代器]
L -- 否 --> N[初始化数据块]
N --> O{异步预取开启?}
O -- 是 --> P[AsyncInitDataBlock首次尝试]
P -- 返回TryAgain --> Q[设置async_read_in_progress_=true]
O -- 否 --> R[InitDataBlock同步初始化]
Q --> S[结束首次调用]
R --> M
M --> T[执行数据块Seek]
T --> U[FindKeyForward前向查找]
U --> V[检查边界条件]
V --> W[断言验证位置]
W --> Z[结束流程]
B -- 否 --> X[SeekSecondPass二次处理]
X --> Y[AsyncInitDataBlock二次尝试]
Y --> T
首次调用流程
首次调用判断:SeekImpl进入之后判断是否是首次调用。如果是首次调用,则设置用于读取预取修剪的前缀键,以优化读取性能;否则跳转到“SeekSecondPass二次处理”。
设置与重置:在首次调用的情况下,设置seek_key_prefix_for_readahead_trimming_后,重置缓存查找变量,为后续操作做准备。
自动调整判断:判断是否自动调整readahead_size。如果是,设置readahead_cache_lookup_=true,表示启用读取预取缓存查找;否则直接进入“CheckPrefixMayMatch”节点。
前缀匹配检查:在“CheckPrefixMayMatch”节点,检查前缀是否匹配。前缀不匹配则重置数据迭代器,重新开始数据查找;匹配则进一步判断是否需要重新定位索引。
索引重新定位:如果需要重新定位索引,执行IndexIterator.Seektarget操作,对索引进行定位;否则检查是否同一数据块。
数据块处理:检查是否同一数据块且有效。如果是,直接使用现有数据块迭代器;否则初始化数据块。初始化数据块时,判断异步预取是否开启。开启则进行AsyncInitDataBlock首次尝试,若返回TryAgain,设置async_read_in_progress_=true;不开启则同步初始化数据块。
数据查找与结束:数据块初始化后,执行数据块Seek操作,进行数据查找。通过FindKeyForward前向查找,检查边界条件,断言验证位置,最终结束流程。
非首次调用流程
- 二次处理:如果不是首次调用,进入“SeekSecondPass二次处理”,再次尝试AsyncInitDataBlock,然后执行数据块Seek操作,继续后续的数据查找流程,直至结束。
异步预取工作流程:
首次Seek调用:
检查
async_read_in_progress_标志触发
AsyncInitDataBlock(is_first_pass=true)通过
PrefetchIfNeeded发起异步IO请求如果数据不在缓存中,返回
Status::TryAgain设置
async_read_in_progress_=true
二次Seek调用:
进入
SeekSecondPass调用
AsyncInitDataBlock(is_first_pass=false)使用已预取的数据块初始化
block_iter_执行常规Seek操作
总结:
预取机制:系统通过预取数据到缓冲区,减少用户实际读取时的等待时间,提高性能。
异步 IO:文件读取操作是异步的,不会阻塞用户线程,适合处理大量数据或高延迟的 IO 操作。
缓冲区管理:缓冲区会动态分配和清理,确保资源高效利用,同时通过状态标记(如
async_read_in_progress)管理读取过程;回调机制:IO 完成后通过回调通知;
FilePrefetchBuffer结构设计
sequenceDiagram
participant User
participant FilePrefetchBuffer
participant RandomAccessFileReader
participant FileSystem
participant BufferInfo
User->>FilePrefetchBuffer: PrefetchAsync(opts, reader, offset, n, result)
FilePrefetchBuffer->>FilePrefetchBuffer: 中止未完成IO (AbortAllIOs)
FilePrefetchBuffer->>FilePrefetchBuffer: 清理过期数据 (ClearOutdatedData)
alt 数据已在缓冲区
FilePrefetchBuffer->>User: 立即返回Status::OK
else 需要新预取
FilePrefetchBuffer->>BufferInfo: 分配新缓冲区 (AllocateBuffer)
FilePrefetchBuffer->>BufferInfo: 计算预取范围 (ReadAheadSizeTuning)
FilePrefetchBuffer->>RandomAccessFileReader: ReadAsync(请求)
RandomAccessFileReader->>FileSystem: 提交异步IO请求
FileSystem-->>RandomAccessFileReader: 返回IO句柄
RandomAccessFileReader-->>FilePrefetchBuffer: 存储io_handle
FilePrefetchBuffer->>BufferInfo: 标记async_read_in_progress=true
end
loop 异步回调处理
FileSystem->>FilePrefetchBuffer: PrefetchAsyncCallback(请求结果)
FilePrefetchBuffer->>BufferInfo: 更新缓冲区数据
FilePrefetchBuffer->>BufferInfo: async_read_in_progress=false
end
User->>FilePrefetchBuffer: TryReadFromCache
FilePrefetchBuffer->>BufferInfo: 检查数据有效性
BufferInfo-->>User: 返回数据切片
用户发起预取请求
向 FilePrefetchBuffer 发起
PrefetchAsync请求,传入参数包括选项(opts)、文件读取器(reader)、偏移量(offset)、预取字节数(n)以及结果回调(result)。这是整个流程的起点,用户希望从文件的某个位置开始预取数据。
预取缓冲区的初始化操作
FilePrefetchBuffer 收到请求后,首先执行两个内部操作:
中止未完成的 IO 操作(AbortAllIOs):确保没有遗留的 IO 请求在处理,避免冲突。
清理过期数据(ClearOutdatedData):移除缓冲区中不再需要或已经失效的数据,为新数据腾出空间。
检查数据是否已在缓冲区
FilePrefetchBuffer 检查请求的数据是否已经存在于缓冲区中。
如果数据已在缓冲区(数据已在缓冲区分支):
- 直接向 User 返回
Status::OK,表示预取成功,无需进一步操作。
- 直接向 User 返回
如果需要新预取(需要新预取分支):
FilePrefetchBuffer 向 BufferInfo 发起两个请求:
分配新缓冲区(AllocateBuffer):为即将预取的数据分配新的缓冲空间。
计算预取范围(ReadAheadSizeTuning):根据策略计算本次预取的实际范围,可能比用户请求的范围更大,以提高效率。
FilePrefetchBuffer 调用 RandomAccessFileReader 的
ReadAsync方法,发起异步读取请求。RandomAccessFileReader 将读取请求提交给 FileSystem,由后者执行实际的 IO 操作。
FileSystem 返回 IO 句柄给 RandomAccessFileReader,后者将其存储在 FilePrefetchBuffer 中。
FilePrefetchBuffer 通过 BufferInfo 标记
async_read_in_progress=true,表示异步读取正在进行。
异步回调处理
当 FileSystem 完成 IO 操作后,会触发回调
PrefetchAsyncCallback,将请求结果传递给 FilePrefetchBuffer。FilePrefetchBuffer 收到回调后,通过 BufferInfo 更新缓冲区数据,并将
async_read_in_progress标记为false,表示读取完成。这个过程可能循环多次,处理多个 IO 请求的回调。
- 用户尝试从缓存读取数据
User 调用 FilePrefetchBuffer 的
TryReadFromCache方法,尝试从缓冲区中读取数据。FilePrefetchBuffer 通过 BufferInfo 检查数据的有效性,确保数据完整且可用。
最终,BufferInfo 将数据切片返回给 User,完成整个流程。
TryReadFromCache
graph TD
A[TryReadFromCache调用] --> B{数据在缓冲区?}
B -- 是 --> C[直接返回数据]
B -- 否 --> D{需要预取?}
D -- 是 --> E[触发Prefetch/PrefetchAsync]
E --> F{同步模式?}
F -- 是 --> G[同步读取数据到缓冲区]
F -- 否 --> H[提交异步IO请求]
H --> I[注册回调函数]
I --> J[后台处理IO完成]
J --> K[更新缓冲区状态]
D -- 否 --> L[返回未命中]
subgraph 异步处理流程
H --> M[文件系统处理请求]
M --> N[数据就绪触发回调]
N --> O[将数据拷贝到缓冲区]
O --> P[标记IO完成]
end
检查数据是否在缓冲区
判断数据是否已经在缓冲区中:
如果数据在缓冲区,直接返回数据,流程结束。
如果数据不在缓冲区,进入下一步判断是否需要预取。
判断是否需要预取
判断当前情况下是否需要进行数据预取:
如果需要预取,触发
Prefetch或PrefetchAsync操作,进入预取流程。如果不需要预取,直接返回未命中结果,流程结束。
预取流程
触发预取操作:根据配置或策略,决定是进行同步预取还是异步预取。
同步模式判断:判断是否采用同步模式进行预取:
如果是同步模式,直接进行同步读取数据到缓冲区的操作。
如果是异步模式,提交异步IO请求,并注册回调函数,等待后台处理IO完成。
异步处理流程
提交异步IO请求:将IO请求提交给文件系统。
注册回调函数:为IO完成事件注册回调函数,以便在数据就绪时进行后续处理。
后台处理IO完成:在后台等待IO操作完成。
更新缓冲区状态:IO完成后,更新缓冲区的状态,反映数据已加载到缓冲区。
异步完成流程
文件系统处理请求:文件系统接收到IO请求后,进行相应的处理。
数据就绪触发回调:当数据准备就绪时,触发之前注册的回调函数。
将数据拷贝到缓冲区:在回调函数中,将数据从文件系统拷贝到缓冲区。
标记IO完成:完成数据拷贝后,标记IO操作为已完成。
BlockFetcher类设计
classDiagram
class BlockFetcher {
-file_ : RandomAccessFileReader*
-prefetch_buffer_ : FilePrefetchBuffer*
-heap_buf_ : CacheAllocationPtr
-compressed_buf_ : CacheAllocationPtr
-direct_io_buf_ : AlignedBuf
-ReadBlock(bool) : void
-TryGetFromPrefetchBuffer() : bool
-TryGetSerializedBlockFromPersistentCache() : bool
+ReadBlockContents() : IOStatus
}
class FilePrefetchBuffer {
+TryReadFromCache(...) : bool
}
class PersistentCacheHelper {
+LookupUncompressed(...) : Status
+InsertSerialized(...) : void
}
class RandomAccessFileReader {
+Read(...) : IOStatus
+MultiRead(...) : IOStatus
}
BlockFetcher --> FilePrefetchBuffer : 使用
BlockFetcher --> PersistentCacheHelper : 使用
BlockFetcher --> RandomAccessFileReader : 使用
BlockFetcher --> Compression : 解压处理
FilePrefetchBuffer:
BlockFetcher通过其prefetch_buffer_属性与FilePrefetchBuffer交互,调用TryReadFromCache方法尝试从预取缓冲区获取数据。PersistentCacheHelper:
BlockFetcher使用PersistentCacheHelper来从持久化缓存中获取未压缩数据或插入序列化数据。RandomAccessFileReader:
BlockFetcher通过file_属性与RandomAccessFileReader交互,直接从文件读取数据。Compression:
BlockFetcher在需要时调用Compression组件进行解压处理。
ReadBlock 流程
sequenceDiagram
participant Caller
participant BlockFetcher
participant PersistentCache
participant FilePrefetchBuffer
participant FileReader
Caller->>BlockFetcher: ReadBlockContents()
alt 持久化缓存命中
BlockFetcher->>PersistentCache: LookupUncompressed
PersistentCache-->>BlockFetcher: 返回未压缩块
else 预取缓冲区命中
BlockFetcher->>FilePrefetchBuffer: TryReadFromCache
FilePrefetchBuffer-->>BlockFetcher: 返回数据切片
BlockFetcher->>BlockFetcher: 处理尾部校验
else 需要文件读取
BlockFetcher->>BlockFetcher: PrepareBufferForBlockFromFile
BlockFetcher->>FileReader: Read/MultiRead
FileReader->>FileSystem: 提交IO请求
FileSystem-->>FileReader: 返回数据
FileReader-->>BlockFetcher: 返回IO状态
BlockFetcher->>BlockFetcher: 处理尾部校验
alt 数据压缩
BlockFetcher->>Compression: 解压处理
end
BlockFetcher->>PersistentCache: 插入缓存
end
BlockFetcher-->>Caller: 返回IO状态
调用ReadBlockContents
- 流程起始于
Caller调用BlockFetcher的ReadBlockContents()方法,表示请求读取某个数据块的内容。
- 流程起始于
检查持久化缓存是否命中
BlockFetcher首先尝试从持久化缓存中获取数据,调用PersistentCache的LookupUncompressed方法。如果持久化缓存命中,
PersistentCache返回未压缩块给BlockFetcher,流程直接进入结束步骤,返回IO状态给调用者。如果持久化缓存未命中,流程进入下一步。
检查预取缓冲区是否命中
BlockFetcher调用FilePrefetchBuffer的TryReadFromCache方法,尝试从预取缓冲区中读取数据。如果预取缓冲区命中,
FilePrefetchBuffer返回数据切片给BlockFetcher。BlockFetcher处理尾部校验,确保数据的完整性。流程进入结束步骤,返回IO状态给调用者。
如果预取缓冲区未命中,流程进入下一步。
需要文件读取
BlockFetcher准备从文件中读取数据块,调用自身的PrepareBufferForBlockFromFile方法。BlockFetcher调用FileReader的Read/MultiRead方法,提交IO读取请求。FileReader与文件系统交互,提交IO请求给FileSystem。FileSystem处理IO请求后,将数据返回给FileReader。FileReader将IO状态返回给BlockFetcher。BlockFetcher处理尾部校验,确保数据的完整性。如果数据是压缩的,
BlockFetcher调用Compression组件进行解压处理。BlockFetcher将解压后的数据插入到PersistentCache中,以便后续读取可以命中缓存。流程进入结束步骤,返回IO状态给调用者。
返回IO状态
- 无论通过哪种方式获取数据,
BlockFetcher最终都会将IO状态返回给Caller,表示读取操作的结果。
- 无论通过哪种方式获取数据,
graph TD
Start[ReadBlockContents调用] --> CheckPersistentCache{持久缓存检查}
CheckPersistentCache -- 命中 --> ReturnOK[返回成功]
CheckPersistentCache -- 未命中 --> CheckPrefetch{预取缓冲检查}
CheckPrefetch -- 命中 --> VerifyChecksum[校验数据]
VerifyChecksum -- 失败 --> RetryRead[重试读取]
CheckPrefetch -- 未命中 --> ReadFromFile[文件读取]
ReadFromFile --> PrepareBuffer[准备缓冲区]
PrepareBuffer --> SelectBuffer{选择缓冲策略}
SelectBuffer -- 小数据 --> UseStackBuf[栈缓冲]
SelectBuffer -- 压缩数据 --> UseCompressedBuf[压缩缓冲]
SelectBuffer -- 普通数据 --> UseHeapBuf[堆缓冲]
ReadFromFile --> PerformIO[执行IO操作]
PerformIO -- 直接IO --> DirectIORead[对齐读取]
PerformIO -- 普通IO --> NormalRead[常规读取]
PerformIO --> CheckIntegrity[完整性检查]
CheckIntegrity -- 损坏 --> RetryRead
CheckIntegrity -- 正常 --> ProcessTrailer[处理尾部]
ProcessTrailer --> Decompress{需要解压?}
Decompress -- 是 --> Uncompress[解压数据]
Decompress -- 否 --> StoreResult[存储结果]
Uncompress --> UpdateCache[更新缓存]
StoreResult --> UpdateCache
UpdateCache --> ReturnOK
流程再次重申:
缓存优先策略:流程首先尝试从持久化缓存和预取缓冲区中获取数据,只有在两者都未命中时才进行文件读取,这种策略可以显著提高读取性能,减少IO操作的开销。
数据完整性校验:在从不同来源获取数据后,都会进行尾部校验,确保数据的完整性和正确性。
异步IO处理:异步IO操作,提高系统的并发处理能力。
缓存更新:在从文件读取数据并解压后,会将数据插入到持久化缓存中,这样后续的读取请求可以直接命中缓存,避免重复的文件读取和解压操作。
graph LR
A[读取请求] --> B{缓冲策略选择}
B -->|小数据| C[栈缓冲 stack_buf_]
B -->|压缩数据| D[压缩池 compressed_buf_]
B -->|普通数据| E[堆缓冲 heap_buf_]
B -->|直接IO| F[对齐缓冲 direct_io_buf_]
C & D & E & F --> G[BlockContents]
G --> H[用户返回后释放]
这里再放一张BlockFetcher中的设计巧思,针对不同的数据大小,区分了不同的缓存池,能够针对不同的IO特点进行特定优化。
简单的bench
生成命令:
1 | rocks_db_bench —db=prefix_scan —env_uri=ws://ws.flash.ftw3preprod1 -logtostderr=false |
数据库结构
Level 0: 包含 4 个 SST 文件,大小分别为 24828520、49874113、100243447、201507232 字节
Level 1: 包含 6 个 SST 文件,总大小为 405046844 字节
Level 2: 包含 13 个 SST 文件,总大小为 814190051 字节
Level 3: 包含 23 个 SST 文件,总大小为 1515327216 字节
Scan :
1 | rocks_db_bench -use_existing_db=true —db=prefix_scan -benchmarks="seekrandom" -key_size=32 |
测试结果:
- 启用异步扫描
- Latency (micros/op) 414442.3
- Throughput (MB/s) 326.2
- IOPS (ops/sec) 9
- Operations 581
- Found Keys 145/145
- 禁用异步扫描
- Latency (micros/op) 848858.67
- Throughput (MB/s) 158.1
- IOPS (ops/sec) 4
- Operations 284
- Found Keys 74/74
总结
RocksDB针对原本LevelDB再SSTable读取过程中遇到的多次IO进行细节化的Prefetch,在Open和Get不同阶段进行针对性的Prefetch动作;
在Open阶段中,Prefetch了所需的Footer内容,一次IO,后续对MetaIndexBlock、FilterBlock的读取都是放在内存中进行,提高效率;在Get阶段中,在具体的SeekImpl实现中,使用异步Block读取,来优化首次读取的性能,减少了用户等待的时间。
针对Prefetch和异步的需求,分开设计了FilePrefetchBuffer和BlockFetcher两个核心类,FilePrefetchBuffer优化SSTable中的Prefetch读取,并结合BlockCache将读入的Block存入内存中,BlockFetcher类独立了Block的异步化读取操作,结合持久化缓存、BlockCache、Prefetch、文件系统级别的Prefetch,解压为一体,向上层提供了简洁的Block读取操作,屏蔽了错综复杂的IO逻辑;
RocksDB-源码分析(1)BlockTable 读源码分析

